
BIG DATA ANALYTICS USING HADOOP
A
Seminar Report submitted to Savitribai Phule Pune University,Ganeshkhind
In partial Fulfillment for the awards of Degree of Engineering in Computer Engineering
Submitted by
Sarita Bagul T120414208
Under the Guidance of
Asst.Prof.B.A.Khivsara
March,2016 - 17
Department of Computer Engineering
SNJB’S Late Sau. Kantabai Bhavarlalji Jain,
College of Engineering, Chandwad
Dist:Nashik

SNJB’S Late Sau. Kantabai Bhavarlalji Jain,
College of Engineering, Chandwad
Dist:Nashik
Department of Computer Engineering
2016-17
Certificate
This is to certify that the Seminar Report entitled Big Data Analytics using Hadoop sub-
mitted by Ms. Sarita Bagul is a record of bonafied work carried out at SNJB’s K. B. Jain
College of Engineering during academic year 2016-17, which affiliated to the Savitribai Phule
Pune University.
Date:
Place: Chandwad
Seminar Guide
Asst.Prof.B.A.Khivsara
Prof. K.M. Sanghavi Dr. M.D.Kokate,
HOD Principal
Department of Computer Engineering
Examiner:.......................................................................................................

Acknowledgement
I would like to acknowledge all the people who have been of the help and assisted
me throughout my project work. First of all I would like to thank my respected guide
Asst.Prof.B.A.Khivsara, Assistant Professor in Department of Computer Engineering for in-
troducing me throughout features needed. The time-to-time guidance, encouragement, and
valuable suggestions received from him are unforgettable in my life. This work would not
have been possible without the enthusiastic response, insight, and new ideas from her.
I am also grateful to all the faculty members of SNJB’s College of Engineering for
their support and cooperation.
I would like to thank my lovely parents for time-to-time support and encourage-
ment and valuable suggestions, and thank my friends for their valuable support and encour-
agement.
The acknowledgement would be incomplete without mention of the blessing of the
Almighty, which helped me in keeping high moral during most difficult period.
Sarita Bagul
i

Abstract
The process of analyzing and mining Big Data is nothing but the Big data analyt-
ics. Big data is a collection of large data sets that include different types such as structured,
unstructured and semi-structured data. Now days, the challenge is extracting meaningful
information and analyzing Big Data .In this report we first introduce the general background
of big data. Big data exceeds the processing capability of traditional database to capture,
manage, and process the voluminous amount of data.
Big data, which refers to the data sets that are too big to be handled using the
existing database management tools, are emerging in many important applications, such as
Internet search, business informatics, social networks, social media, genomics, and meteo-
rology. Big data presents a grand challenge for database and data analytics research. In this
talk, I review the exciting activities in my group addressing the big data challenge.
In this talk, I review about technique how Big Data is analyzed by using the tech-
nique of Hadoop and then focus on hadoop platform using map reduce algorithm which pro-
vide the environment to implement application in distributed environment. Since Hadoop
has emerged as a popular tool for Big data implementation, this report deals with the overall
architecture of Hadoop along with the details of its various components. Hadoop is designed
to scale up from a single server to thousands of machines, with a very high degree of fault
tolerance.
Keywords:Big data, Map Reduce, HDFS, Hadoop.
ii

Contents
Acknowledgement i
Abstract ii
1 Introduction 1
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Characteristics Of Big Data . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Big Data Analytics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Features Of Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Literature Survey 5
2.1 MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 MapReduce Architecture . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Advantages Of MapReduce . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.3 Disadvantages Of MapReduce . . . . . . . . . . . . . . . . . . . . . . 7
2.1.4 Application Of MapReduce . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 NoSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Features Of NoSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 Characteristics Of NoSQL . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.3 NoSQL Categories . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.4 Advantages Of NoSQL . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.5 Disadvantages Of NoSQL . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Hadoop As An Open Source Tool For Big Data Analytics . . . . . . . . . . . 13
2.3.1 Hadoop Technology Stack . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 Components Of Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 Working Of Hadoop 15
3.1 Architecture of Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Hadoop Distributed File System (HDFS) . . . . . . . . . . . . . . . . 16
3.2 Hadoop Operation Modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
iii
3.3 Installation And Setup Of Hadoop . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.1 Installing Hadoop in Standalone Mode . . . . . . . . . . . . . . . . . 19
3.3.2 Installing Hadoop in Pseudo Distributed Mode . . . . . . . . . . . . . 20
3.3.3 Verifying Hadoop Installation . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Some essential Hadoop project . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Application Of Big Data Analytics Using Hadoop 26
4.1 Application Of Big Data Analytics Using Hadoop . . . . . . . . . . . . . . . 26
4.2 Health Care Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2.1 Hadoop Technology In Monitoring Patient Vitals . . . . . . . . . . . 27
5 Advantages/Disadvantages of Hadoop 28
5.1 Advantages Of Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.2 Disadvantages Of Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
6 Conclusion 30
6.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
7 Bibliography 31
iv

List of Figures
1.1 5 Vs Of Big Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Value Of Big Data Analytics . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 MapReduce Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 NoSQL Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Key Value Store . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 Graph Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5 Hadoop Technology Stack . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1 Hadoop Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 HDFS Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Core-site.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4 hdfs-site.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5 hdfs-file.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.6 yarn-site.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.7 mapred-site.xml . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.8 Hadoop on Browser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.9 Hadoop application on Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1 Hadoop Technology In Monitoring Patient Vitals . . . . . . . . . . . . . . . 27
v
Chapter 1
Introduction
1.1 Introduction
A massive volume of both structured and unstructured data that is so large
that it’s difficult to process with traditional database and software techniques.The users
are producing more and more data through communication media in the unstructured form
which is highly unmanageable and this management of data is the challenging job. The main
focus is to gather the unstructured data, processed the data to convert into structured form
so that accessing of the data would be easier . Accordingly, data is analyzed and processed to
convert it into meaningful and right information by using the concept of Big Data Analytics.
An example of big data may be Exabytes of data consisting of trillions of records
of millions of people from different sources such as websites, social media, mobile data, web
servers, online transactions and so on[1].
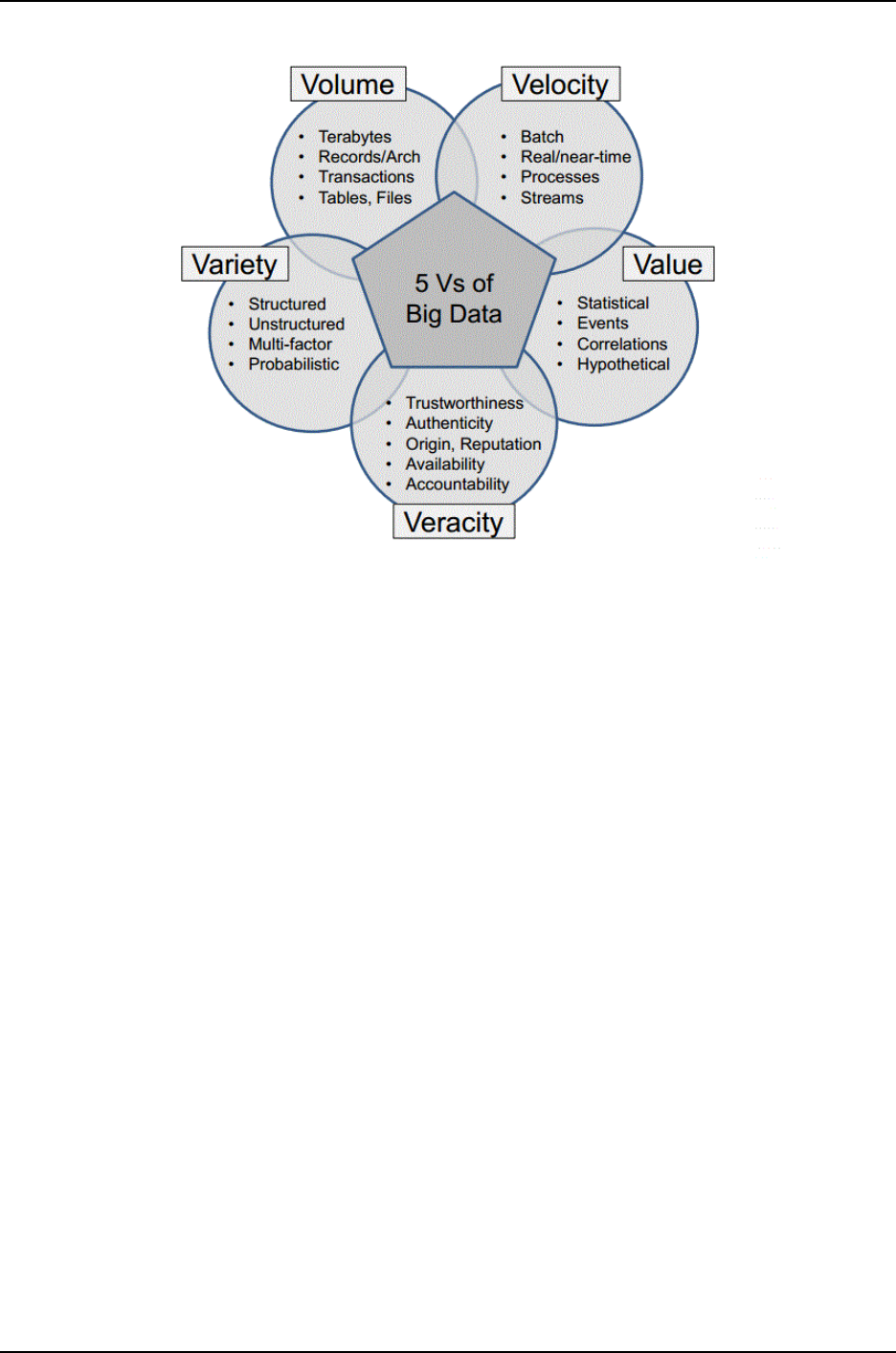
1.1.1 Characteristics Of Big Data
[4]As the data is too big and comes from various sources in different form, it is characterized
by the following five components:
• Volume: The quantity of generated and stored data. The size of the data determines
the value and potential insight and whether it can actually be considered big data or
not.
• Variety: The type and nature of the data. This helps people who analyze it to
effectively use the resulting insight.
• Velocity: In this context, the speed at which the data is generated and processed to
meet the demands and challenges that lie in the path of growth and development.
• Value: Inconsistency of the data set can hamper processes to handle and manage it.
1
CHAPTER 1. INTRODUCTION
Figure 1.1: 5 Vs Of Big Data
• Veracity: The quality of captured data can vary greatly, affecting accurate analysis.
1.2 Big Data Analytics
Big Data analytics is the process of analyzing and mining Big Data. Big data ana-
lytics is the process of analyzing big data to find hidden patterns, unknown correlations and
other useful information that can be extracted to make better decisions.Big data analytics
is where advanced analytic techniques operate on big data sets. Hence, big data analytics
is really about two thingsbig data and analytics plus how the two have teamed up to create
one of the most profound trends in business intelligence (BI) today[11].Big data analytics is
helpful in managing more or diverse data.
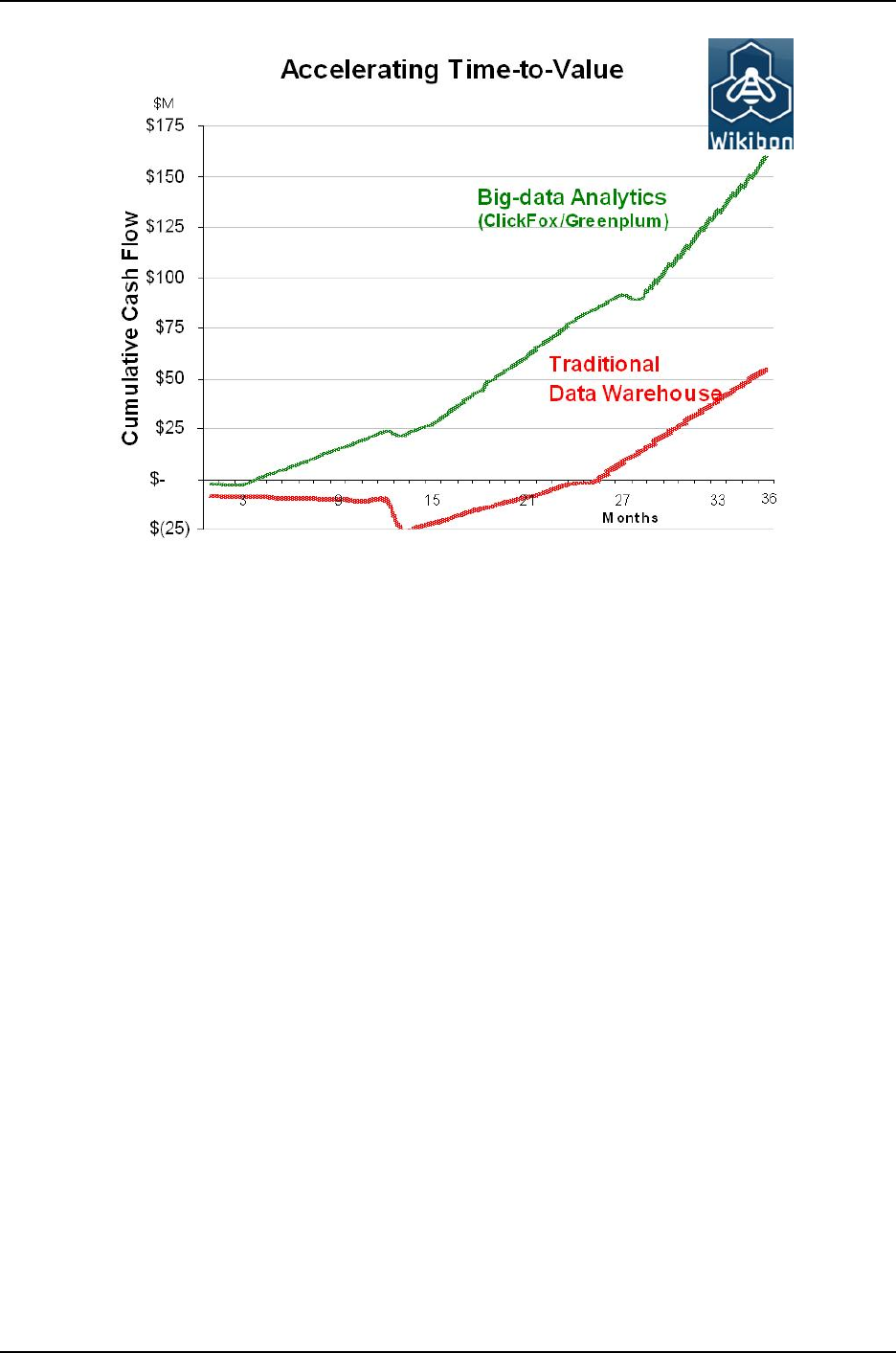
Figure 1.2 is demonstrating the value of Big Data Analytics by drawing the graph
between time and cumulative cash flow. Old analytics techniques like any data warehousing
application, you have to wait hours or days to get information as compared to Big Data
Analytics. Information has the timeliness value when it is processed at right time otherwise
it would be of no use. It might not return its value at proper cost.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 2
CHAPTER 1. INTRODUCTION
Figure 1.2: Value Of Big Data Analytics
1.3 Hadoop
Hadoop is an open source, Java-based programming framework that supports
the processing and storage of extremely large data sets in a distributed computing envi-
ronment[7]. Hadoop is used to develop applications that could perform complete statistical
analysis on huge amounts of data.
Hadoop is by far the most popular implementation of MapReduce, being an en-
tirely open source platform for handling Big Data. Hadoop runs applications using the
MapReduce algorithm, where the data is processed in parallel on different CPU nodes. In
short, Hadoop framework is capable enough to develop applications capable of running on
clusters of computers and they could perform complete statistical analysis for huge amounts
of data.
Hadoop has two major layers namely:
• 1.Processing/Computation layer (Map Reduce), and
• 2.Storage layer (Hadoop Distributed File System)[1].
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 3

CHAPTER 1. INTRODUCTION
1.4 Features Of Hadoop
• Scalability: Nodes can be easily added and removed. Failed nodes can be easily
detected.
• Low cost: As Hadoop is an open source framework,it is free. It commodity hardware
to store and process huge data.Hence not much costly.
• High computing power: Hadoop uses distributed computing model.Due to this task
can be distributed amongst different nodes and can be processed quickly.
• Huge and Flexible storage: Massive data storage is available due to thousands of
nodes in the cluster.It supports both structured and unstructured data.No preprocess-
ing is required on data before storing it.
• Fault tolerance and data protection:If any node fails the task in hand are au-
tomatically Redirected to other nodes.Multiple copies of all data are automatically
stored.
• Economical: It distributes the data and processing across clusters of commonly avail-
able computers (in thousands).
• Efficient: By distributing the data, it can process it in parallel on the nodes where
the data is located.
• Reliable: It automatically maintains multiple copies of data and automatically rede-
ploys computing tasks based on failures[18].
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 4
Chapter 2
Literature Survey
This survey illustrated that in olden days through RDBMS tools ,the data was
less and easily handled by RDBMS but recently it is difficult to handle huge data, which
is preferred as data.[2]. Big data exhibits different characteristics like volume, variety, vari-
ability, value, velocity and complexity due to which it is very difficult to analyse data and
obtain information with traditional data mining techniques[1].
The tools used for mining big data are apache hadoop, apache pig, cascading,
scribe, storm, apache Hbase etc. Thus, instructed that our ability to handle many Exabyte.s
of data mainly dependent on existence of rich variety dataset, technique, software framework.
There are many old technologies already present used for big data handling but each one of
them has some advantages and disadvantages. There are number of technologies are there
few of them are mentioned below:
• Column-oriented databases
• NoSQL databases
• MapReduce
• Hive
• Pig
• WibiData
• PLATFORA
• Apache Zeppelin
• Hadoop
5
CHAPTER 2. LITERATURE SURVEY
2.1 MapReduce
MapReduce provides analytical capabilities for analyzing huge volumes of complex
data. The Map Reduce program is an Apache open-source framework which runs on Hadoop.
MapReduce is a software framework. Data processing is done by MapReduce.MapReduce
scales and runs an application to different cluster machines.
2.1.1 MapReduce Architecture
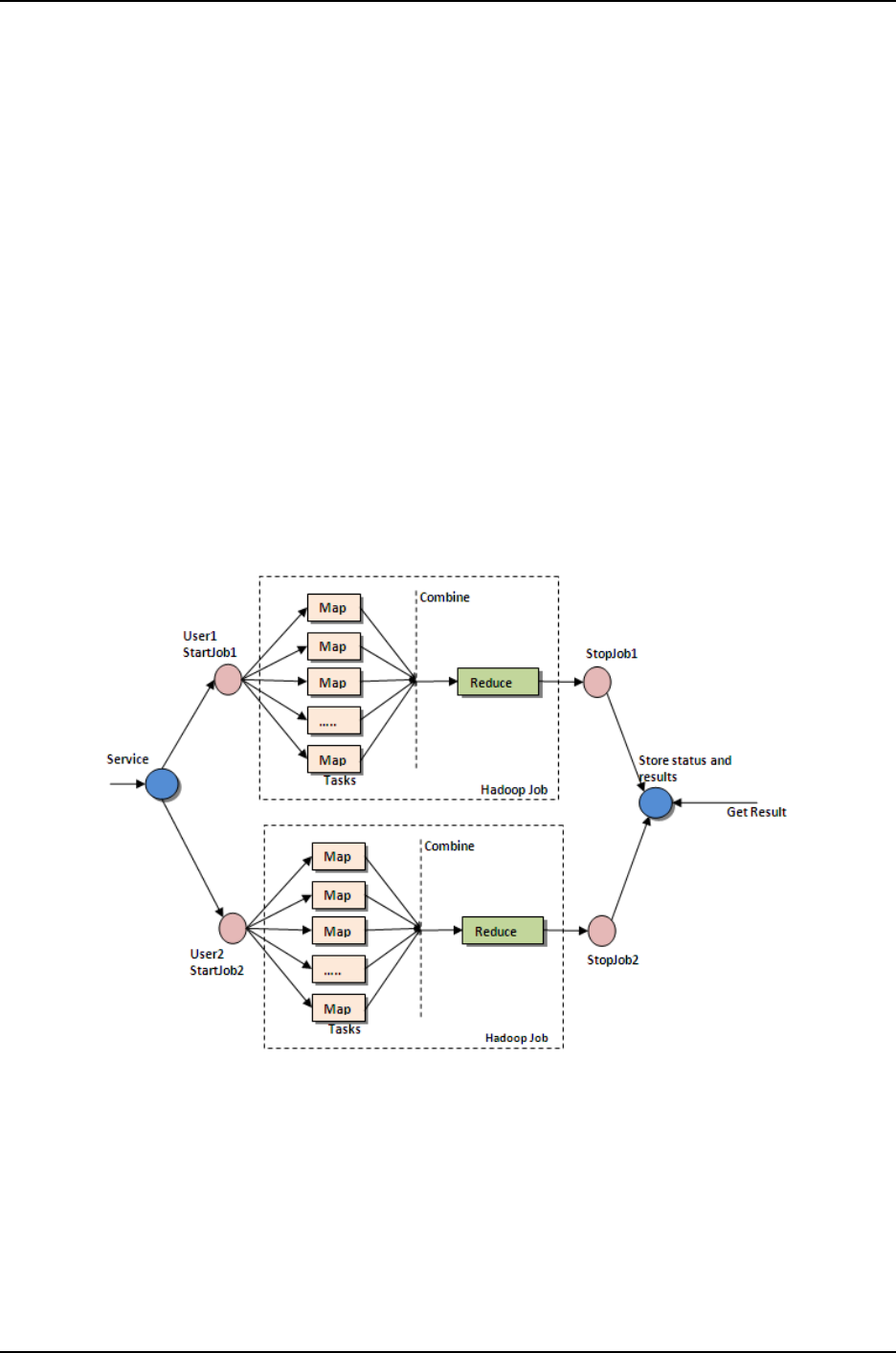
MapReduce works by breaking the processing into two phases: the map and re-
duce.Each phase has a key-value pairs as input and output,the type of which may be chosen
by the programmer.The major advantage of Map Reduce is that it is easy to scale data pro-
cessing over multiple computing nodes. Under the Map Reduce model, the data processing
primitives are called mappers and reducers.
Figure 2.1: MapReduce Architecture
Mapping and Reducing are two important phases for executing an application
program.In the Mapping phase MapReduce takes input data, filters that input data and then
transform each data element to the mapper.In the Reducing phase, the reducer processes
all the outputs from the mapper, aggregates all and the outputs and then provides a final
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 6

CHAPTER 2. LITERATURE SURVEY
result.Decomposing a data processing application into mappers and reducers is sometimes
nontrivial.This simple scalability is what has attracted many programmers to use the Map
Reduce model[1].
• map: the function takes key/value pairs as input and generates an intermediate set of
key/value pairs.
• reduce: the function which merges all the intermediate values associated with the
same intermediate key.
2.1.2 Advantages Of MapReduce
• Scalability
• Cost-effective solution
• Flexibility
• Fast
• Security and Authentication
• Parallel processing
• Availability and resilient nature
2.1.3 Disadvantages Of MapReduce
• Batch processing, not interactive.
• Design for a specific problem domain.
• MapReduce programming paradigm not commonly understood.
• The index generated in the Map step is one dimensional, and the Reduce step must not
generate a large amount of data or there will be a serious performance degradation.
• MapReduce may not be a good fit for full-text indexing or ad hoc searching.
• Lack of trained support professional.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 7

CHAPTER 2. LITERATURE SURVEY
2.1.4 Application Of MapReduce
• Distributed Grep
• Large-Scale PDF Generation
• Artificial Intelligence
• Geographical data
2.2 NoSQL
[13] NoSQL (originally referring to SQL. or relational.) database provides a mech-
anism for storage and retrieval of data that is modeled in means other than the tabular
relations used in relation databases (RDBMS). It encompasses a wide variety of different
database technologies that were developed in response to a rise in the volume of data stored
about users, objects and products, the frequency in which this data is accessed, and per-
formance and processing needs. Generally, NoSQL databases are structured in a key-value
pair, graph database, document-oriented or column-oriented structure.
2.2.1 Features Of NoSQL
[14]Complexity of SQL query Burden of up-front schema design DBA presence Transac-
tions(It should be handled at application layer) Easy and frequent changes to DB Fast
development Large data volumes(eg.Google) Schema less Open source development.
2.2.2 Characteristics Of NoSQL
• Almost infinite horizontal scaling
• Simpler and faster
• No fixed table schemas
• No join operations
• Structured storage
• Almost everything happens in RAM[14]
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 8

CHAPTER 2. LITERATURE SURVEY
Figure 2.2: NoSQL Architecture
2.2.3 NoSQL Categories
[15] are four general types (most common categories) of NoSQL databases. Each
of these categories has its own specific attributes and limitations. There is not a single
solutions which is better than all the others, however there are some databases that are
better to solve specific problems. To clarify the NoSQL databases, lets discuss the most
common categories :
• Key-value stores
• Column-oriented
• Graph
• Document oriented
Key-Value Store
• Key-value stores are most basic types of NoSQL databases.
• Designed to handle huge amounts of data.
• Based on Amazons Dynamo paper.
• Key value stores allow developer to store schema-less data.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 9
CHAPTER 2. LITERATURE SURVEY
• In the key-value storage, database stores data as hash table where each key is unique
and the value can be string, JSON, BLOB (Binary Large Object)etc.
• For example a key-value pair might consist of a key like ”Name” that is associated
with a value like ”Robin”.
• A key may be strings, hashes, lists, sets, sorted sets and values are stored against these
keys.
• Key-Value stores can be used as collections, dictionaries, associative arrays etc.
• Key-Value stores follow the ’Availability’ and ’Partition’ aspects of CAP theorem.
• Key-Values stores would work well for shopping cart contents, or individual values like
color schemes, a landing page URI, or a default account number.
Figure 2.3: Key Value Store
Example of Key-value store DataBase : Redis, Dynamo, Riak. etc.
Column-Oriented Databases
• Column-oriented databases primarily work on columns and every column is treated
individually.
• Values of a single column are stored contiguously.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 10
CHAPTER 2. LITERATURE SURVEY
• Column stores data in column specific files.
• In Column stores, query processors work on columns too.
• All data within each column datafile have the same type which makes it ideal for
compression.
• Column stores can improve the performance of queries as it can access specific column
data.
• High performance on aggregation queries (e.g. COUNT, SUM, AVG, MIN, MAX).
• Works on data warehouses and business intelligence, customer relationship manage-
ment (CRM), Library card catalogs etc.
Example of Column-oriented databases : BigTable, Cassandra, SimpleDB etc.
Graph Databases
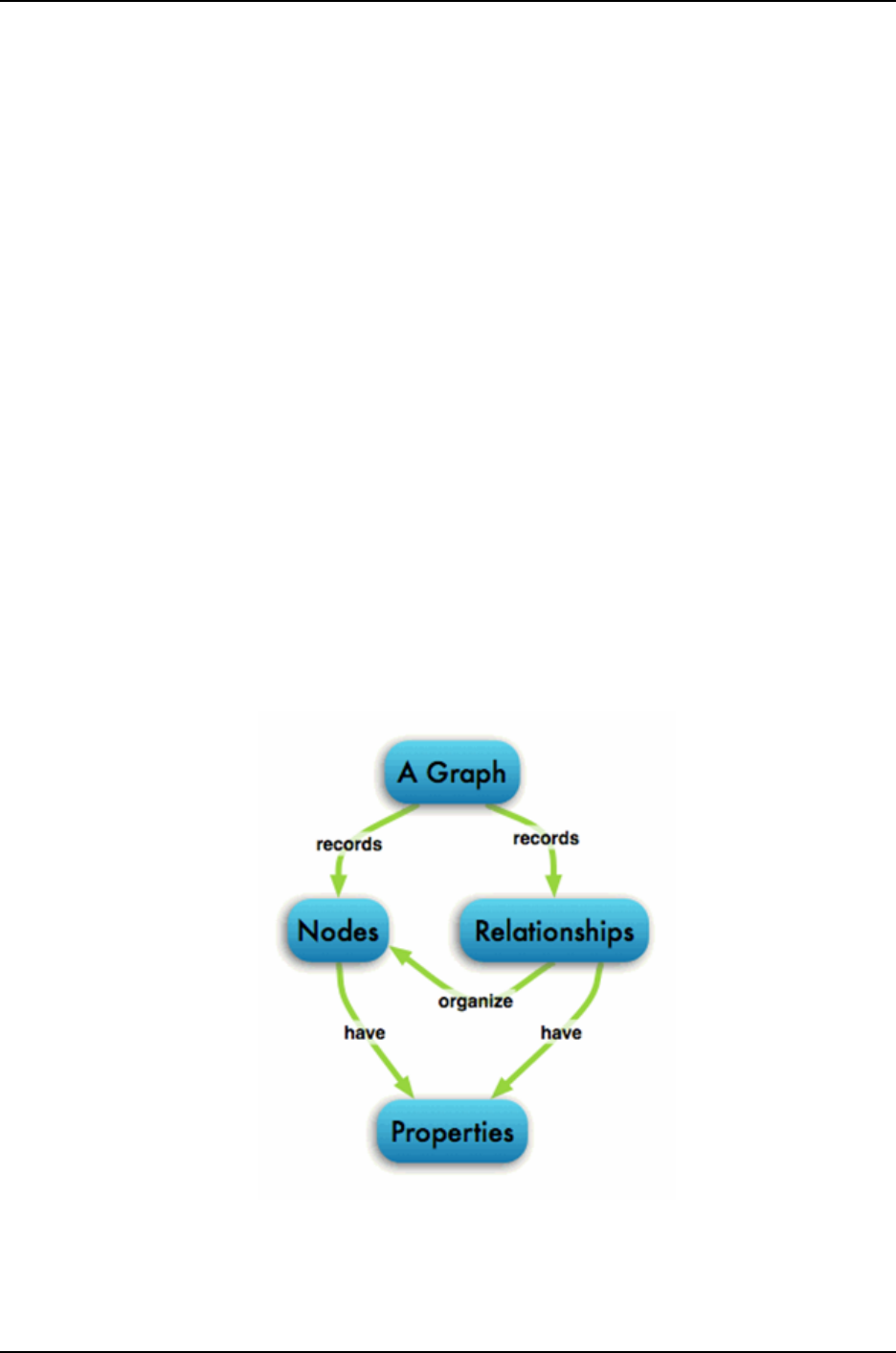
A graph data structure consists of a finite (and possibly mutable) set of ordered
pairs, called edges or arcs, of certain entities called nodes or vertices. The following picture
presents a labeled graph of 6 vertices and 7 edges.
Figure 2.4: Graph Database
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 11

CHAPTER 2. LITERATURE SURVEY
• A graph database stores data in a graph.
• It is capable of elegantly representing any kind of data in a highly accessible way.
• A graph database is a collection of nodes and edges.
• Each node represents an entity (such as a student or business) and each edge represents
a connection or relationship between two nodes.
• Every node and edge are defined by a unique identifier.
• Each node knows its adjacent nodes.
• As the number of nodes increases, the cost of a local step (or hop) remains the same.
Example of Graph databases : OrientDB, Neo4J, Titan.etc.
Document Oriented Databases
• A collection of documents.
• Data in this model is stored inside documents.
• A document is a key value collection where the key allows access to its value.
• Documents are not typically forced to have a schema and therefore are flexible and
easy to change.
• Documents are stored into collections in order to group different kinds of data.
• Documents can contain many different key-value pairs, or key-array pairs, or even
nested documents.
Example of Document Oriented databases : MongoDB, CouchDB etc.
2.2.4 Advantages Of NoSQL
• High scalability[16]
• Distributed Computing[16]
• Lower cost[16]
• Schema flexibility, semi-structure data[16]
• No complicated Relationships[16]
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 12

CHAPTER 2. LITERATURE SURVEY
• It supports query language.
• It provides fast performance.
• It provides horizontal scalability.
2.2.5 Disadvantages Of NoSQL
• No standardization
• Limited query capabilities (so far)
• Eventual consistent is not intuitive to program[16].
2.3 Hadoop As An Open Source Tool For Big Data
Analytics
[3] Hadoop is a distributed software solution. It is a scalable fault tolerant dis-
tributed system for data storage and processing.There are two main components in Hadoop.
Figure 2.5: Hadoop Technology Stack
• 1)HDFS (which is a storage)
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 13

CHAPTER 2. LITERATURE SURVEY
• 2)MapReduce (which is retrieval and processing).
The hadoop core/common which consists of HDFS (Distributed Storage) which is a pro-
grammable interface to access stored data in cluster.
2.3.1 Hadoop Technology Stack
YARN (Yet Another Resource Negotiation) : Its a Map Reduce version 2. This is
future stuff. This is stuff which is currently alpha and yet to come. It is rewrite of Map
Reduce 1[3].
2.4 Components Of Hadoop
• Avro: A serialization system for efficient,cross-language PRC and persistent data
storage.
• Pig:A data flow language and execution environment for exploring very large dataset.
Pig runs on HDFS and MapReduce clusters.
• Hive:Distributed data warehouse .Hive manages data stored in HDFS and provides a
query language based on SQL for querying the data.
• HBase:A distributed,column-oriented database. HBase uses HDFS for its underly-
ing storage, and supports both batch-style computations using Mapreduce and point
queries.
• ZooKeeper: A distributed,highly available coordination service. ZooKeeper provides
primitives such as distributed locks that can be used for building distributed applica-
tions.
• Sqoop:A tool for efficient bulk transfer of data between structured data stores and
HDFS.
• Oozie:A service for running and scheduling workflows of Hadoop jobs[5].
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 14

Chapter 3
Working Of Hadoop
3.1 Architecture of Hadoop
Figure 3.1: Hadoop Architecture
[18] Hadoop is an open source, Java-based programming framework that supports
the processing and storage of extremely large data sets in a distributed computing envi-
ronment. Hadoop is used to develop applications that could perform complete statistical
analysis on huge amounts of data.
Hadoop architecture includes following four modules:
• Hadoop Common: These are Java libraries and utilities required by other Hadoop
15

CHAPTER 3. WORKING OF HADOOP
modules. This library provides OS level abstractions and contains the necessary Java
files and scripts required to start Hadoop.
• Hadoop YARN: This is a framework for job scheduling and cluster resource man-
agement.
• MapReduce: MapReduce is a software framework. Data processing is done by
MapReduce.MapReduce scales and runs an application to different cluster machines.
• Hadoop Distributed File System (HDFS): The Hadoop Distributed File System
(HDFS) is a distributed file system designed to run on commodity hardware. It has
many similarities with existing distributed file systems.
3.1.1 Hadoop Distributed File System (HDFS)
The Hadoop Distributed File System (HDFS) is a distributed file system designed
to run on commodity hardware. It has many similarities with existing distributed file sys-
tems. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It
provides high throughput access to application data and is suitable for applications having
large datasets. To interact with HDFS hadoop provides a command interface[1].
Figure 3.2: HDFS Architecture
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 16

CHAPTER 3. WORKING OF HADOOP
For distributed storage and distributed computation Hadoop uses a master/slave
architecture.The distributed storage system in hadoop is called as Hadoop Distributed File
System or HDFS. A client interacts with HDFS by communicating with the NameNode and
DataNodes.The user does not know about the assignment of NameNode and DataNode for
functioning.i.e which NameNode and DataNode are assigned or will be assigned. HDFS
follows the master-slave architecture and it has the following elements.
1.NAME NODE
The name node is the commodity hardware that contains the GNU/Linux operating system
and the name node software. It is software that can be run on commodity hardware. The
system having the name node acts as the master server and it does the following tasks:
Manages the file system namespace. Regulates client.s access to files and It also executes
file system operations such as renaming, closing, and opening files and directories[1].
2.DATA NODE
The data node is a commodity hardware having the GNU/Linux operating system and data
node software. For every node (Commodity hardware/System) in a cluster, there will be
a data node. These nodes manage the data storage of their system. Data nodes perform
read-write operations on the file systems, as per client request. They also perform operations
such as block creation, deletion, and replication according to the instructions of the name
node[1].
3.BLOCK
Generally the user data is stored in the files of HDFS. The file in a file system will be divided
into one or more segments and/or stored in individual data nodes. These file segments are
called as blocks. In other words, the minimum amount of data that HDFS can read or write
is called a Block. The default block size is 64MB, but it can be increased as per the need to
change in HDFS configuration[1].
3.2 Hadoop Operation Modes
Once you have downloaded Hadoop, you can operate your Hadoop cluster in one
of the three supported modes
• Local/Standalone Mode: After downloading Hadoop in your system, by default, it
is configured in a standalone mode and can be run as a single java process.
• Pseudo Distributed Mode: It is a distributed simulation on single machine. Each
Hadoop daemon such as hdfs, yarn, MapReduce etc., will run as a separate java process.
This mode is useful for development.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 17

CHAPTER 3. WORKING OF HADOOP
• Fully Distributed Mode: This mode is fully distributed with minimum two or more
machines as a cluster. We will come across this mode in detail in the coming chapters.
3.3 Installation And Setup Of Hadoop
[17] Before installing Hadoop into the Linux environment, we need to set up Linux
using ssh (Secure Shell). Follow the steps given below for setting up the Linux environment.
1.Creating a User
Open the Linux terminal and type the following commands to create a user.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd
2.SSH Setup And Key Generation
The following commands are used for generating a key value pair using SSH. Copy
the public keys form id rsa.pub to authorized keys, and provide the owner with read and
write permissions to authorized keys file respectively.
$ ssh-keygen -t rsa
$ cat /.ssh/id rsa.pub >> ~/.ssh/authorized keys
$ chmod 0600 ~/.ssh/authorized keys
3.Installing Java
First of all, you should verify the existence of java in your system using the command -
version.. The syntax of java version command is given below.
$ java -version
If everything is in order, it will give you the following output.
java version
¨
1.7.0 71”
Java(TM) SE Runtime Environment (build 1.7.0 71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
4.Downloading Hadoop
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 18

CHAPTER 3. WORKING OF HADOOP
Download and extract Hadoop 2.4.1 from Apache software foundation using the following
commands.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit
3.3.1 Installing Hadoop in Standalone Mode
Step 1: Setting Up Hadoop
You can set Hadoop environment variables by appending the following commands to /.bashrc
file.
export HADOOP HOME=/usr/local/hadoop
Before proceeding further, you need to make sure that Hadoop is working fine. Just issue
the following command:
$ hadoop version
If everything is fine with your setup, then you should see the following result:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
It means your Hadoop’s standalone mode setup is working fine. By default, Hadoop is con-
figured to run in a non-distributed mode on a single machine
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 19

CHAPTER 3. WORKING OF HADOOP
3.3.2 Installing Hadoop in Pseudo Distributed Mode
Step 1: Setting Up Hadoop
You can set Hadoop environment variables by appending the following commands to /.bashrc
file.
export HADOOP HOME=/usr/local/hadoop
export HADOOP MAPRED HOME=HADOOP HOME
exportHAD OOP COMMON HOME =HADOOP HOME
export HADOOP HDFS HOME=HADOOP HOME
exportY ARN HOME =HADOOP HOME
export HADOOP COMMON LIB NATIVE DIR=HADOOP HOME/lib/native
exportP AT H =PATH:HADOOP HOME/sbin :HADOOP HOME/bin
export HADOOP INSTALL=HADOOP HOME
Now apply all the changes into the current running system.
$ source ~/.bashrc
Step 2: Hadoop Configuration
You can find all the Hadoop configuration files in the location $HADOOP HOME/etc/hadoop..
It is required to make changes in those configuration files according to your Hadoop infras-
tructure.
$ cd HADOOP HOME/etc/hadoop
In order to develop Hadoop programs in java, you have to reset the java environment vari-
ables in hadoop-env.sh file by replacing JAVA HOME value with the location of java in your
system.
export JAVA HOME=/usr/local/jdk1.7.0 71
The following are the list of files that you have to edit to configure Hadoop.
core-site.xml
The core-site.xml file contains information such as the port number used for Hadoop in-
stance, memory allocated for the file system, memory limit for storing the data, and size of
Read/Write buffers.
Open the core-site.xml and add the following properties in between < configuration > ,
< /configuration > tags.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 20

CHAPTER 3. WORKING OF HADOOP
Figure 3.3: Core-site.xml
hdfs-site.xml
The hdfs-site.xml file contains information such as the value of replication data, namenode
path, and datanode paths of your local file systems. It means the place where you want to
store the Hadoop infrastructure.
Figure 3.4: hdfs-site.xml
Open this file and add the following properties in between the < conf iguration > , <
/configuration > tags in this file.
Figure 3.5: hdfs-file.xml
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 21

CHAPTER 3. WORKING OF HADOOP
Note: In the above file, all the property values are user-defined and you can make changes
according to your Hadoop infrastructure.
yarn-site.xml
This file is used to configure yarn into Hadoop. Open the yarn-site.xml file and add the
following properties in between the < configuration > , < /configuration > tags in this
file.
Figure 3.6: yarn-site.xml
mapred-site.xml
This file is used to specify which MapReduce framework we are using. By default, Hadoop
contains a template of yarn-site.xml. First of all, it is required to copy the file from mapred-
site,xml.template to mapred-site.xml file using the following command.
$ cp mapred-site.xml.template mapred-site.xml
Open mapred-site.xml file and add the following properties in between the < configur ation >
, < /configuration > tags in this file.
Figure 3.7: mapred-site.xml
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 22

CHAPTER 3. WORKING OF HADOOP
3.3.3 Verifying Hadoop Installation
The following steps are used to verify the Hadoop installation.
Step 1: Name Node Setup
Set up the namenode using the command namenode -format. as follows.
$ cd
$ hdfs namenode -format
The expected result is as follows.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP MSG:
/************************************************************
STARTUP MSG: Starting NameNode
STARTUP MSG: host = localhost/192.168.1.11
STARTUP MSG: args = [-format]
STARTUP MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN MSG:
/************************************************************
SHUTDOWN MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
Step 2: Verifying Hadoop dfs
The following command is used to start dfs. Executing this command will start your Hadoop
file system.
$ start-dfs.sh
The expected output is as follows:
10/24/14 21:37:56
Starting namenodes on [localhost]
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 23
CHAPTER 3. WORKING OF HADOOP
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
Step 3: Verifying Yarn Script
The following command is used to start the yarn script. Executing this command will start
your yarn daemons.
$ start-yarn.sh
The expected output as follows:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
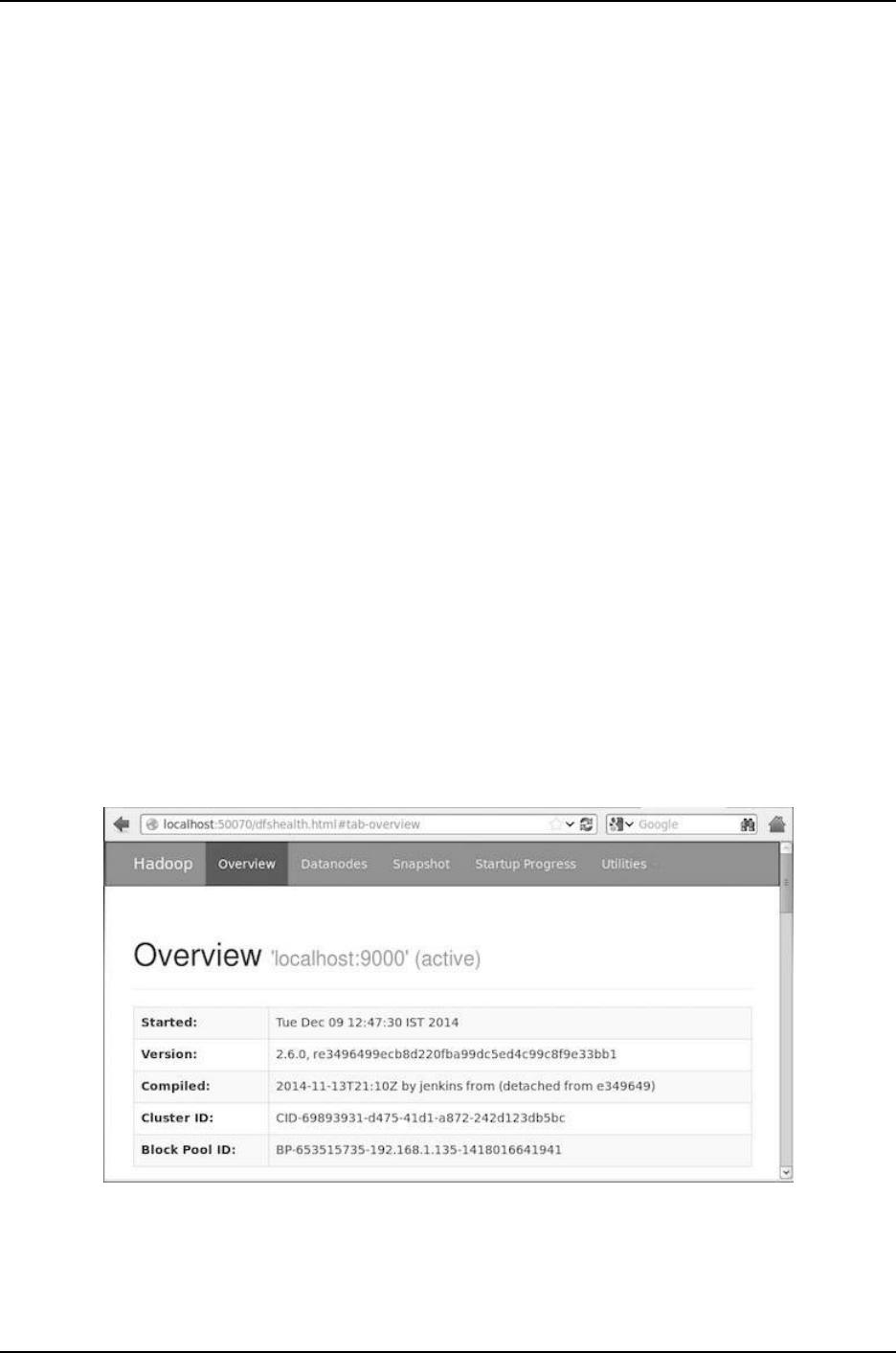
Step 4: Accessing Hadoop on Browser
The default port number to access Hadoop is 50070. Use the following url to get Hadoop
services on browser.
http://localhost:50070/
Figure 3.8: Hadoop on Browser
Step 5: Verify All Applications for Cluster
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 24

CHAPTER 3. WORKING OF HADOOP
The default port number to access all applications of cluster is 8088. Use the following url
to visit this service.
http://localhost:8088/
Figure 3.9: Hadoop application on Cluster
3.4 Some essential Hadoop project
• Pig Latin: which is a programming language.
• Pig Runtime:which competes pig latin and converts it into map reduce job to submit
to cluster.
• Data Intelligence:We also have data intelligence in the form of Drill and Mahout.
• Drill:Drill is actually an incubator project and is designed to do interactive analysis
on nested data.
• Mahout: Mahout is a machine learning library that concurs the three Cs :
1. Recommendation (Collaborative Filtering)
2. Clustering (which is a way to group related text and documents)
3. Classification (which is a way to categorize related text and documents)[3].
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 25
Chapter 4
Application Of Big Data Analytics
Using Hadoop
4.1 Application Of Big Data Analytics Using Hadoop
• Health Care Applications
• IOT
• Social Media
• Advertisement (Mining user behavior to generate recommendations)
• Searches (group related documents)
• Searches (group related documents)
4.2 Health Care Applications
• Hadoop technology in Monitoring Patient Vitals
• Hadoop technology in Cancer Treatments and Genomics
• Hadoop technology in the Hospital Network
• Hadoop technology in Healthcare Intelligence
• Hadoop technology in Fraud Prevention and Detection[17].
26

CHAPTER 4. APPLICATION OF BIG DATA ANALYTICS USING HADOOP
4.2.1 Hadoop Technology In Monitoring Patient Vitals
There are several hospitals across the world that use Hadoop to help the hospital
staff work efficiently with Big Data. Without Hadoop, most patient care systems could not
even imagine working with unstructured data for analysis.
Figure 4.1: Hadoop Technology In Monitoring Patient Vitals
Childrens Healthcare of Atlanta treats over 6,200 children in their ICU units. On
average, the duration of stay in Pediatric ICU varies from a month to a year. Childrens
Healthcare of Atlanta used a sensor beside the bed that helps them continuously track
patient signs such as blood pressure, heartbeat and the respiratory rate. These sensors
produce large chunks of data, which using legacy systems cannot be stored for more than
3 days for analysis.The main motive of Childrens Healthcare of Atlanta was to store and
analyze the vital signs. If there is any change in pattern, then the hospital wanted an alert
to be generated to a team of doctors and assistants. All this was successfully achieved using
Hadoop ecosystem components - Hive, Flume, Sqoop, Spark, and Impala[17].
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 27
Chapter 5
Advantages/Disadvantages of Hadoop
5.1 Advantages Of Hadoop
• Scalable: Hadoop is a highly scalable storage platform, because it can stores and
distribute very large data sets across hundreds of inexpensive servers that operate in
parallel.
• Flexible: Hadoop enables businesses to easily access new data sources and tap into
different types of data (both structured and unstructured) to generate value from that
data.
• Cost effective: Hadoop also offers a cost effective storage solution for businesses
exploding data sets.
• Resilient To Failure:A key advantage of using Hadoop is its fault tolerance. When
data is sent to an individual node, that data is also replicated to other nodes in the
cluster, which means that in the event of failure, there is another copy available for
use.
• Fast: The tools for data processing are often on the same servers where the data is
located, resulting in much faster data processing. If youre dealing with large volumes
of unstructured data, Hadoop is able to efficiently process terabytes of data in just
minutes, and petabytes in hours[12].
5.2 Disadvantages Of Hadoop
• Security Concerns: Just managing a complex applications such as Hadoop can be
challenging. A simple example can be seen in the Hadoop security model, which
is disabled by default due to sheer complexity. If whoever managing the platform
28

CHAPTER 5. ADVANTAGES/DISADVANTAGES OF HADOOP
lacks of know how to enable it, your data could be at huge risk. Hadoop is also
missing encryption at the storage and network levels, which is a major selling point
for government agencies and others that prefer to keep their data under wraps[12].
• Not Fit For Small Data: Due to its high capacity design, the Hadoop Distributed
File System, lacks the ability to efficiently support the random reading of small files.
As a result, it is not recommended for organizations with small quantities of data[12].
• Vulnerable By Nature: Speaking of security, the very makeup of Hadoop makes
running it a risky proposition. The framework is written almost entirely in Java, one
of the most widely used yet controversial programming languages in existence[12].
• Hadoop can perform only batch processing and sequential access.Sequential access is
time consuming.So a new technique is needed to get rid of this problem.
• Hadoop can perform only batch processing and sequential access.Sequential access is
time consuming.So a new technique is needed to get rid of this problem.
• Disk based processing: slow
• Many tools to enhance Hadoop’s capabilities.
• Not for interactive and iterative.
• Multiple copies of already big data.
• Lack of required skills.
• Very limited SQL support.
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 29
Chapter 6
Conclusion
6.1 Conclusion
We Studied the concept of Big Data along with 5 Vs,volume ,velocity ,variety
,value and veracity of Big Data. Today data is generated in large amount ,to process these
large amounts of data is a big issue. The paper describes Hadoop which is an open source
software used for processing of Big Data in detail. Apache Hadoop is open source, and pio-
neered a fundamentally new way of storing and processing data. Hadoop enables distributed
parallel processing of huge amounts of data across inexpensive, industry-standard servers
that both store and process the data, and can scale without limits. Hadoops breakthrough
advantages mean that businesses and organizations can now find value in data that was
recently considered useless.
We also discussed some hadoop components which are used to support the pro-
cessing of large data sets in distributed computing environments.
30

Chapter 7
Bibliography
[1] Sethy, Rotsnarani, and Mrutyunjaya Panda ”Big Data Analysis using Hadoop:
A Survey.” International Journal 5.7 (2015).
[2] Bhosale, Harshawardhan S., and Devendra P. Gadekar. ”A Review Paper on Big
Data and Hadoop.” International Journal of Scientific and Research Publications
4.10 (2014): 1.
[3] ]http://research.ijcaonline.org/volume108/number12/pxc3900288.pdf
[4] https://en.wikipedia.org/wiki/Big data
[5] Tom White,.Hadoop, The definitive guide.,OfReilly,3rd Edition
[6] https://www.google.co.in/?gfe rd=cr&ei=ayKnWJWmDe x8AfDyLnQDg&gws rd=ssl#q
= hadoop + tutorial + ppt
[7] https://www.google.co.in/?gfe rd=cr&ei=ayKnWJWmDe x8AfDyLnQDg&gws rd=ssl#q
= hadoop
[8] Bernice Purcell The emergence of gbig datah technology and analytics Journal
of Technology Research 2013.
[9] https://www.google.co.in/search?q=Hadoop%2 C + a + distributed + framework +
for + Big + Data &ie=utf-8&oe¯utf-8 &client = firefox − b − ab&gfe rd = cr&ei =
glXJW JyDMIKM4gL89IP ACg
[10] Gupta, Bhawna, and Kiran Jyoti.”Big data analytics with hadoop to analyze
targeted attacks on enterprise data.” (IJCSIT) International Journal of Com-
puter Science and Information Technologies 5.3 (2014): 3867-3870.
31

CHAPTER 7. BIBLIOGRAPHY
[11] Russom, Philip.”Big data analytics.” TDWI best practices report, fourth quarter
(2011): 1-35.
[12] http://blogs.mindsmapped.com/bigdatahadoop/hadoop-advantages-and-disadvantages/
[13] http://www.tutorialspoint.com/articles/ what − is − nosql − and − is − it − the −
next − big − trend − in − databases
[14] http://www.tutorialspoint.com/MongoDB/MongoDB-Application.htm
[16] http://www.w3resource.com/mongodb/nosql.php
[17] https://www.dezyre.com/article/5-healthcare-applications-of-hadoop-and-big-data/85
[18] https://www.tutorialspoint.com/hadoop/hadoop.htm
SNJB’s Late Sau. K. B. Jain College of Engineering, Chandwad, Dist. Nashik. 32
